TLDR
Staked chased technical performance over double-signing robustness and that’s not a good trade off. No customers were harmed in this interaction but it was an expensive lesson for Staked and we are sharing our learnings in case they help others.
What happened:
75 Staked-run validators were slashed on February 2. This was a Staked technical issue, so our customers will be fully compensated. But what went wrong and how can you learn from our mistakes?
What went wrong:
We made the mistake of chasing attestation performance at the expense of reliability in attestation. Even though we have an internal mantra to always choose robustness over downtime, we still went awry.
ETH2 has led to a new set of performance criteria. The block explorers all publish attestation rate (the percentage of time you successfully sign blocks when you are scheduled to do so). This impacts customer revenue, so we've been very focused our customers earn the highest yields. That means a sharp focus on this chart:
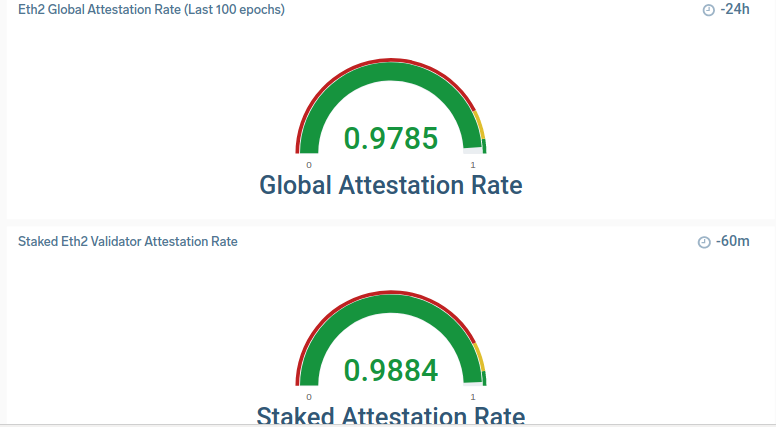
Over the past six weeks, we have rolled out a set of performance improvements to deliver a higher attestation rate. We test those using a "canary" environment and roll them out to a broader set of validators.
We’ve identified a number of items that helped us improve significantly, two of which matter for this discussion:
- Prysm’s on-client slashing protection database was a heavy user of I/O and causing attestation misses (they've since fixed this). Since we have we have a separate layer of double signing protection that uses Hashicorp Consul, we stopped persisting this across restarts of the validator clients.
- Ensuring that beacon node instances have the right ratio of signing validators and are highly performant.
This combination led to our undoing. We attempted to scale up the number of beacon nodes to get better performance. While we had tested in our canary environment, the production load that we were trying to alleviate behaved differently, causing our validators to restart more frequently than we'd seen in testing. Because we had disabled the persistence of #1 above, these validators signed a second version of the same blocks: a major issue that led to a slashing event.
What's the lesson learned?
Obviously, we should not have disabled the persistence of Prysm's database in pursuit of better performance. The performance gains we achieved weren't worth the additional risk we inadvertently added. While this seems obvious, we thought we had reliable protection via Consul. But a belt-and-suspenders approach here would have been more prudent.
Testing for scale is hard. We should have ensured new beacon nodes were fully-synced and connected to lots of peers before allowing them to connect to validator clients. This is hard to do on existing testnets, but we should have developed an internal version to test this.
What are we doing differently?
We are now persisting the Prysm slashing DB to validators running in all five regions, so this issue can’t happen again.
We have instituted new changes to the way we deploy new beacon nodes such that they can't participate with validators until they are fully-synced.
What happens to impacted clients?
Staked will reimburse clients for both slashed ETH and lost rewards. We will contact impacted clients with details on how this will happen.
On a more personal note, Seth (CTO) and Tim(CEO) drafted this, this sucks and we're sorry. We let customers down and need to do better. We will get better and deliver the reliability you should expect from Staked.